Сама крутая фантазия людей на тему умного дома звучит так: "щелкаешь пальцами и свет включается". Даже не знаю, почему ни один известный мне производитель до сих пор не выпустил соответствующую железку-отслеживатель щелчков : )
На самом деле, лично мне бы очень понравилось управлять своим домом с помощью голоса! И возможности хотя бы частично реализовать эту функцию уже начинают появляться на горизонте.
Начну с того, что существующие на рынке движки распознавания речи от Яндекс и Google уже можно пытаться использовать в своих проектах.
Яндекс позволяет любому желающему получить тестовый доступ к SpeechKit Cloud сроком на 1 месяц. В пределах этого срока можно делать до 100 запросов в сутки. Дальнейший доступ к движку уже платный, в качестве ориентира указывается цена $5 за 1000 запросов.
Доступ к Google Speech API в данный момент достаточно нетривиален, но зато не ограничен тестовым периодом. Любой, кто имеет учетку / мыло от Google, может зарегистрироваться как участник проекта Chromium-dev , после чего зайти в Developers Console, где можно создать свой собственный проект и наконец-то получить ключ к Speech API. Теперь можно делать до 50 запросов в сутки.
ЭКСПЕРИМЕНТ #1
Естественно, чтобы распознать голос, нужно его откуда-то получить! И первым делом я обратил внимание на завалявшуюся у меня после давних экспериментов плату Silabs PoE-VOICE-RD:

Плата разработчика Silabs PoE-VOICE-RD
На плате есть все необходимое: микрофон, процессор и контроллер Ethernet. В идеале я хотел бы, чтобы плата непрерывно отслеживала уровень фонового шума и при превышении некого порога начинала бы записывать голос, который затем бы самостоятельно отправила движку распознавания речи, а ответ вернула бы контроллеру умного дома. Программу-максимум выполнить не удалось: программирование этой платы оказалось весьма нетривиальной задачей, также катастрофически не хватало оперативной памяти (всего 4кб), а микрофон оказался весьма среднего качества.
Я смог заставить плату передавать UDP-пакеты со звуком с частотой дискретизации 8кГц разрядностью 12 бит. Кроме того, я смог заставить плату отслеживать уровень фоновой громкости. Далее пакеты принимались скриптом PHP, запущенном на ПК, скрипт собирал пакеты вместе, генерировал из них wav-файл и отправлял файл в Яндекс силами консольной утилиты curl:
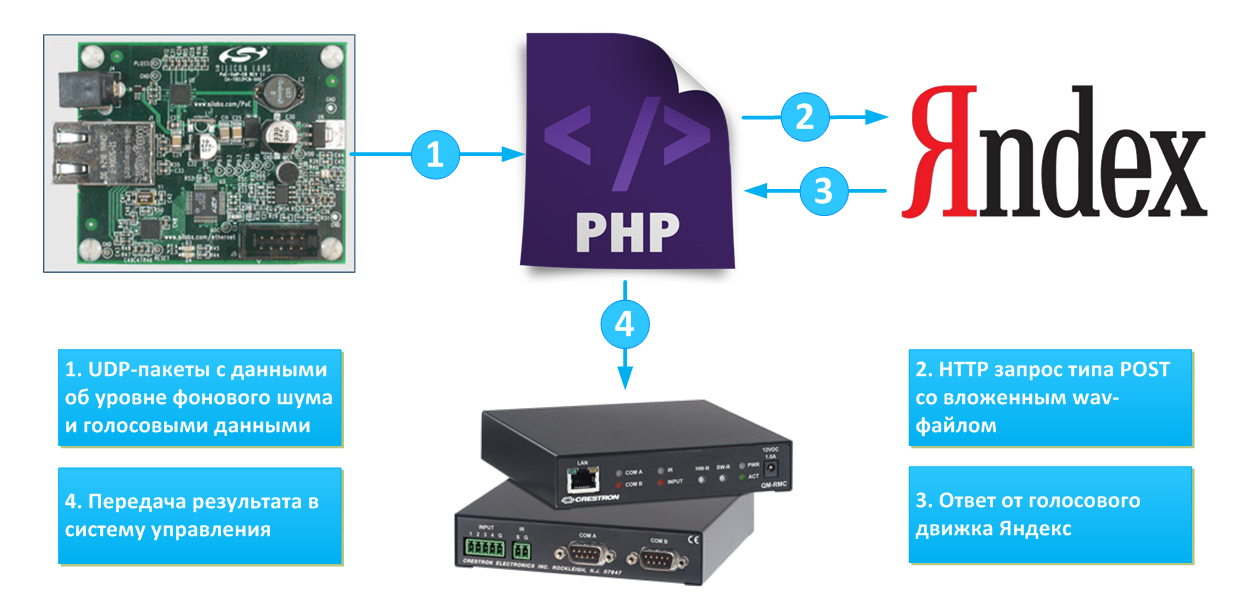
Схема передачи данных в эксперименте 1
Результат эксперимента: итоговое качество распознавания оказалось очень невысоким. В первую очередь это связано с невысоким качеством микрофона, низкой частотой дискретизации и небольшой разрядностью оцифровки.
ЭКСПЕРИМЕНТ #2
Некоторые сенсорные панели управления имеют функцию интеркома по Ethernet. И когда мне предложили купить со скидкой сенсорную панель управления Crestron TPMC-4SM, я сразу же подумал, что можно попробовать использовать возможности интеркома для получения голосовых команд.
Для начала было необходимо взломать протокол обмена информацией между двумя такими панелями во время установки интерком-соединения и передачи голоса между ними. Мне повезло, протокол оказался достаточно простым. Инициализация соединения происходит по TCP/IP, протокол текстовый и в нем всего пара команд и пара оповещений на внятной английском языке. Голосовые данные все так же передаются пакетами UDP, а качество звука оказалось на высоте: полноценные 22кГц разрядностью 16 бит!
После этого я выкинул из системы вторую сенсорную панель, но при этом программно сымитировал ее наличие, инициировал сеанс интерком-соединения и как и в первом эксперименте получил голосовые данные. На этот раз я не контролировал уровень фонового шума, а просто нарисовал кнопку для диктовки команды. Кроме того, вместо скрипта PHP я решил написать консольное приложение на Qt, а для распознавания речи использовал движок Google (тестовый период от Яндекса уже закончился):
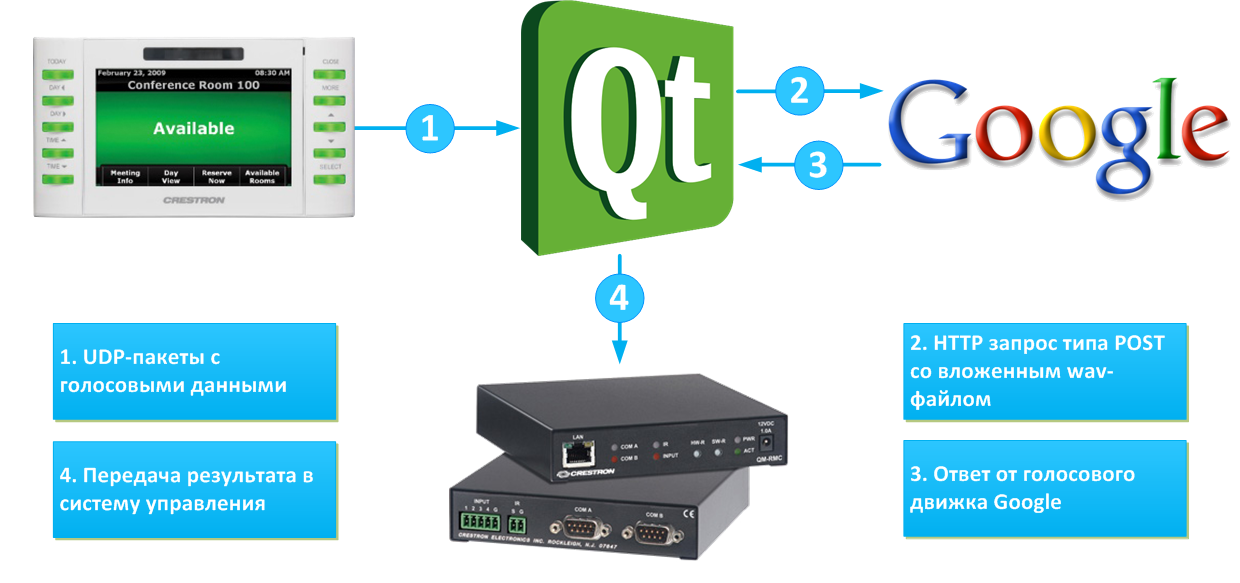
Схема передачи данных в эксперименте 2
На этот раз результат получился куда более интересным. Так что не стыдно приложить и короткий видеоролик : )
Фактически, Гугл будет прослушивать твой дом. Нехорошо.
Только команды, а не непрерывно ) Непрерывно надо развертывать на собственном сервере, с радостью выделил бы под это дело отдельную виртуалку, вот только как бы распознать речь на уровне Яндекса / Гугла )))